大数据虽然已经是大家耳熟能详的热词,但数据领域里的许多术语和概念仍然会让人不明就里,我们从“做饭”这个普通人应该都有基本了解开始给大家介绍大数据虽然已经是大家耳熟能详的热词,但数据领域里的许多术语和概念仍然会让人不明就里,我们从“做饭”这个普通人应该都有基本了解开始给大家介绍

【主菜】
正所谓“巧妇难为无米之炊”,做饭首先得有食材,大数据也一样,没有数据说什么都是扯淡,所以数据就是数据人的食材(只要有数据,我不用吃饭)。
做饭通常都要包括“买菜~洗菜~配菜~炒菜”这几个必须环节,无论你是开饭店还是家里一日三餐,做饭的规模大小会有不同,但流程却是一样的。而这几个环节其实正好对应了数据人的日常工作内容:买菜(数据采集)~洗菜(数据清洗)~配菜(数据建模)~炒菜(数据加工)。
1、买菜(数据采集)
买菜,出门首先要考虑去哪里买,到地之后溜达溜达看看买什么食材,看中一个之后讨价、还价、交钱,肉、蛋、青菜,各种要买的食材都得按这个流程来一遍,买齐之后就走人回家了。
对于数据人来说,我们把这个买菜的过程叫做数据采集。 菜市场就是我们通常所说的数据源。 买菜的选择很多:超市(种类较少,质量上乘),农贸市场(种类较多,菜品一般),露天早市(啥都可能有,运气好还能吃到野味)
数据源其实也一样,数据库(超市)中存储了结构化的业务数据、交易数据,传感器(农贸市场)产生大量半结构化日志数据、机器数据,网络上(早市)
充斥着各种参差不齐的非结构化数据。

到了菜市场我们得选菜,所有的食材我都想吃,但钱永远是不够的,所以我只能有选择性的买,这个过程叫数据调研,哪些数据是有用的,哪些数据用得起,得有个筛选。 溜达了一圈,确定要买猪肉、鸡蛋和黄瓜,得跟卖家挑肥拣瘦、讨价还价、敲定斤两,这个过程叫数据接口规范。 费劲口舌,劳心劳力把菜买齐之后提菜回家,这个过程叫数据传输。 根据买菜方式、习惯的的不一样,数据采集还可以细分出很多类型:
- 肉类保质期长,一次买一周的量,可以叫全量采集。
- 青菜讲究新鲜,每次只买当天的菜,可以叫增量采集。
- 每天早上都得去买菜的,可以叫批量采集。
- 卖家每次上了新菜都主动给你往家送的(土豪专用),可以叫流式采集。

2、洗菜(数据清洗)
洗菜就很好理解了,无论哪里来的食材,都多少存在卫生或者质量问题,买回来后都得洗干净、摘清楚才能吃,不然小则影响口感,大则损害健康。
数据也是一样,拿回来之后得检查一下,数据内容有没有缺斤少两,数据值里有没有烂菜叶,不然后面的报表、分析出来的结果就全是错误结论了,我们把这个检查、纠正数据本身错误的过程叫做数据清洗。
由于数字世界里各种数据源的多样性、复杂度远远高于现实生活里的菜市场,数据清洗流程需要面对和处理的问题也就远远多于洗菜,为了解决和防范数据产生、使用过程中出现的各方面问题,数据领域细分出了一个专门的研究方向叫数据治理,比如:
- 为了了解各个菜市场的情况,我们需要记录每个菜市场、每个卖家的猪肉、鸡蛋、黄瓜等各种食材的大小、颜色、价格等特点,这个叫元数据管理。
- 记录完之后发现每家的特点都不一样,完全没有可比性,于是我们决定对猪肉、鸡蛋、黄瓜的大小、颜色、价格进行统一规定、统一定价,这个叫数据标准管理。
- 定完标准之后,我们得定期对各个菜市场进行检查,看看他们有没有按标准办事,这个叫数据质量管理。

3、配菜(数据建模)
配菜指的是根据要炒什么菜,将需要的各种食材事先搭配好放在一起,比如说我们要炒木须肉,那就把猪肉、鸡蛋、黄瓜都洗净、切好放在一个碗里,这样在炒菜的时候可以手到擒来,无需到处找食材,能够很好的提升炒菜的效率。
一般家庭做饭可能不会严格这么做,但对于餐饮行业来说,这是必备环节,想想买回来一车的食材,洗净、切好之后,如果没有一定的摆放规律,不能充分保证大厨炒菜时的效率,客户半天吃不到菜,那这个饭店的翻台率和回头率绝对高不了,还是趁早关门大吉。
而在数据工程里,也同样有个专业性很强甚至被神话的配菜流程,这就是传说中的数据建模。数据建模就是建立数据存放模型,把各个数据源过来的各种数据根据一定的业务规则或者应用需求对数据重新进行规划、设计和整理。
配菜这个流程也许在做饭过程中不起眼,有时候可有可无,但是在数据工程里,数据建模却是个非常关键的环节.
数据的种类之多、复杂度之高远远超过食材,比如一个银行,内部和业务、流程、管理相关的IT系统一般都超过100个,这也就是100多个菜市场,而每个菜市场能够提供的食材少则数百个,多则成千上万个,这都放在一起就是几十万个食材,再加上外部更加复杂的其他数据源,这么多不同类型、不同标准的食材放在一起,怎么才能让后面的炒菜更加高效和科学,其复杂度和可研究性也的确远远高于真正的配菜。
正因为如此,在数据发展史上出现了不少专业的建模(配菜)方法论:
- 比如说按食材种类进行摆放的(猪肉放一堆,鸡蛋放一堆,黄瓜放一堆),我们叫范式建模,你要是开个火锅店或者准备吃火锅,那肯定是采用范式建模来配菜了
- 比如按菜品种类进行摆放的(炒木须肉的放一堆,炒宫保鸡丁的放一堆),我们叫维度建模,你要是吃个家常炒菜,那采用维度建模方法来配菜就更合理了

各种方法论都有其产生背景、适用场景和支持者,为了不引起战争,这里就不做深入讨论了
在这些方法论基础上,经过不断的实践和研究,一些领先的数据厂商推出了标准的行业数据模型,什么叫行业数据模型呢,因为每个行业的业务特点不一样,比如说银行业、电信业、零售业的业务模式就有很大差异,数据也是不一样的,所以不同行业的数据怎么摆放,数据模型怎么设计,有着很强的行业独特性,每个行业都需要自己特定的数据模型,这叫术业有专攻。
上面这段话没看懂?没事。简单来说,行业数据模型就是“饭店筹备攻略”。
比如说你觉得川菜很赚钱,想开个川菜馆,但你只是个标准吃货,只吃过猪肉没看过猪跑,怎么办?没事,我这有本“川菜开店筹备攻略”,里面什么都有:
- 首先,攻略里会告诉你川菜里有哪些知名、流行、畅销的菜品(比如水煮肉、毛血旺等等),定期更新,图文并茂,这样菜单有了。
- 其次,每个菜品应该用什么样的食材,分别的配比是什么样的,攻略里已经终结出来了,而且是来自各大名厨的经验和终结,于是菜谱也有了。
- 再次,每种食材在后厨的摆放位置是什么样的,这么摆放能够在厨房的有限空间里最大化的提高大厨们工作效率,详细的设计图纸攻略里也给你画好了,这样厨房设计图也有了。
- 最后,我还告诉你每种食材去哪里能买到,哪里最经济实惠,连供应链都帮你打通了
所以,万事具备,只欠东风,你只要找个门面,雇两个蓝翔毕业生,我们就可以开业大吉,财源滚滚了。什么,找门面很麻烦,没事,我们连店面都可以提供,欢迎加入我们的加盟连锁计划,我们不但提供攻略,连店面也一起提供,带精装修的、锅碗瓢盆一应俱全。(文章下方提供攻略)
说点题外话,由于数据建模的专业性太强,非常需要经验的积累,于是在数据行业里衍生了一个专门负责配菜的工种叫“模型设计师”,某全球知名厂商T公司的模型设计师就是业内各大猎头和甲方的香饽饽,T公司一度被挖成重灾区。
4、炒菜(数据加工)
炒菜相信大家都不陌生,如果配菜是个艺术活,那炒菜就绝对是个技术活了。各位大厨不但要有能力把各种食材组合起来炒熟,还得灵活运用油、盐、酱、醋等多种配料,保证菜品的色香味俱全。而且既然是开门迎客,各种消费者的需求都要能够响应,而且要响应的既快又好。
数据加工就是在炒菜,是个将各种数据进行计算、汇总、准备的流程,是为最后的数据应用和数据消费者服务的。客户的要求总是千奇百怪的,所以根据数据消费者的需求不同,数据加工的形式也是百花齐放。
老板们时间宝贵,注重宏观,所以一般只看重要指标,并且要求图文并茂、简单易懂。这就好比皇帝每天都吃满汉全席,所有菜品都是固定的,但是菜品得色香味俱全、上菜速度得快。所以大厨们得事先把数据加工成仪表盘、可视化大屏等让人对关键指标一目了然、并且卖相高大上的数据应用,并且采用各种技术手段保证数据应用的性能(上菜的速度),不然皇帝饿了的时候不能及时上菜,谁都背不起这个锅。
官员们各管一摊,每天都要面对各种日常工作和突发情况,所以他们对数据的要求是既要有常规菜品能满足日常管理需要,也要能有额外菜品来应对突发情况,而且上菜速度也不能慢,县官不如现管嘛。所以参考自助餐的模式,数据大厨们可以将数据加工成多维分析、自助分析这类数据应用,根据经验和官员们的口味爱好,将有可能用到的菜品通通提供出来,官员们饿了的时候可以根据需要随意品尝,贴心又暖胃。
员工们也有数据需求,但通常需求简单,难点在于人多、需求量大,所以将数据加工成报表这种类似于快餐的数据应用就是是最好的方式。
数据加工除了满足以上各种数据需求,还有个不同不提的职责就是数据创新。这就好比为了保证饭店的竞争力和消费者们的新鲜感,不时推出新菜品也是大厨们的职责所在。而在数据圈里,通过数据进行创新已经成为潮流和共识,于是,数据分析师、数据科学家这些角色开始粉末登场。
他们的工作就是通过通过尝试各种数据(食材)和参数(调料)的组合方式来探索和发掘新的业务机会。而由于食材的量实在太大,配料比例的波动范围就更是无止境,难以靠人力把各种组合方式进行穷尽。于是,随着数学理论和技术发展,通过算法让计算机自动进行食材组合、调料配比从而产生新的发现成为可能,也就是我们现场经常听到的数据挖掘、机器学习了。

【甜点】
码字很累,洋洋洒洒写了不少,但感觉有些点还没有写透,有些方面还写的比较牵强,但领会精神最重要,放张大图,大家意会一下吧。
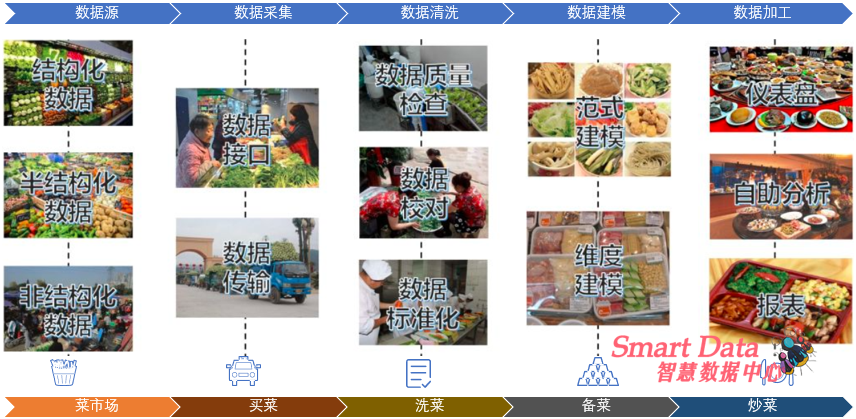
以上参考 燕飞 的"【扫盲贴】讲透大数据,我只需要一顿饭"
基础概念都清楚了, 我们可能要问, 数据分析给我们带来什么价值:
- 打通数据壁垒,实现信息透明。底层搭建数仓,统一数据编码,将多个业务系统数据进行整合,加强部门间信息互通,实现层级间信息垂直透明,促进协作共赢的良好工作氛围
- 提高工作效率,促进业务增值。代替传统手工报表,减少人为干涉错误,提高数据准确性;人效分析,提高生产效率,节约人力成本;产销存平衡分析,缩短周转周期,提高库存周转率、销售转化率,促进业务不断增值
- 数据驱动产品,引导创新改良。维修数据分析,反馈质量问题,促进生产、工艺或设计改良;客户需求反馈分析,定位目标功能,引导产品创新
- 辅助管理预测,提高决策成功率。销售预测分析,辅助市场决策,提高投入产出比;采购预测分析,辅助物料订单管理,提高物料周转率,防止供应商过多备料、物料呆滞
- 内外数据整合,提升市场竞争力。竞品分析、价格带分析、客户满意度分析,作为企业调整战略目标的参考依据,及时抓住市场机会,提升市场竞争力
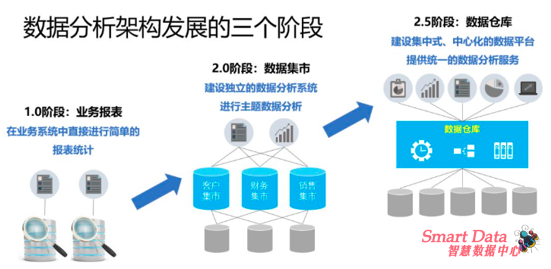
企业如何低成本又高效的实现这些需求:
建意基于自身的数据体量/数据构成/预算 进行考虑
- 首先需要打通数据孤岛, 将企业的线上数据/线下数据/第三方数据进行统一管理, 你需要建立数据仓库
- 选择一个合适的BI产品, 推荐使用成熟的PowerBI或Tableau,找数据分析师也方便, 但是BI的优势在于自助式的探索分析, 但是对数据分析的及时性与可视化定制化效果偏弱, 帐号价格偏高等问题, 所以你可以搭配使用smartchart做为补充, 来实现实时大屏和高度定制化的仪表盘
- 你需要从业务系统中抽取数据到数据仓库, 进行清洗/转化/加载(ETL), 推荐选择免费的Kettle
- 你需要对这些数据处理任务进行依赖和定时的调度管理, 推荐使用免费的调度工具Airflow
- 以上基础的数据分析体系的就完成了, 但是象kettle/airflow/数据仓库/BI工具这些都是独立的, 尤其是免费的开源产品, 企业使用起来是非常麻烦, 你需要一个专业的平台将他们管理起来
- 你可能还需要报表权限的管理和一个统一的可视化平台给用户访问, 用户还会需要一个上传数据和下载数据的入口
- 市面上有很多BI工具自带ETL功能, ETL工具又自带BI功能,数据仓库产品又带ETL又带BI, 看起来很美好, 但是用起来很糟糕, 因为限定太多, 你不能选择优秀的开源产品或其它公司的商业产品, 现在开源产品才是未来. 太商业化的东西不便于定制化
- SmartData数据服务平台是基于最佳的企业应用实践开发,不单独开发数据仓库或BI产品,仅联结全球联先的数据分析产品,精选开源产品,可高度定制,解决企业数据分析管理过程中的痛点, 帮助企业搭建专业的数据分析平台
关注抖音号,不定期直播答疑,聊聊数字化这些事
