经常会这样的一些需求, 比如一个数据集可能不足以完成一个图形, 这些数据有可能来源不同的系统, 有可能是因为结构不一样, 不合适进行sql拼接, 还有可能这个数据集需要同时应用不同的图形.
其实我们只要灵活应用下smartchart就可以实现了. 首先, 将你的数据集名称命名为"common.xxxxx", 即为通用数据集, 通用数据集的图形中只需写为:
data__name__ = __dataset__;如下图: 注意图形所在的序号, 后续在其它图形中的引用就是data序号, 这个就是data0. 另外"DIV格式"留空, 这样就是一个纯净的数据集了. 由于公用的数据集需要提前加载, 所以请尽量把它们的顺序排在最前面
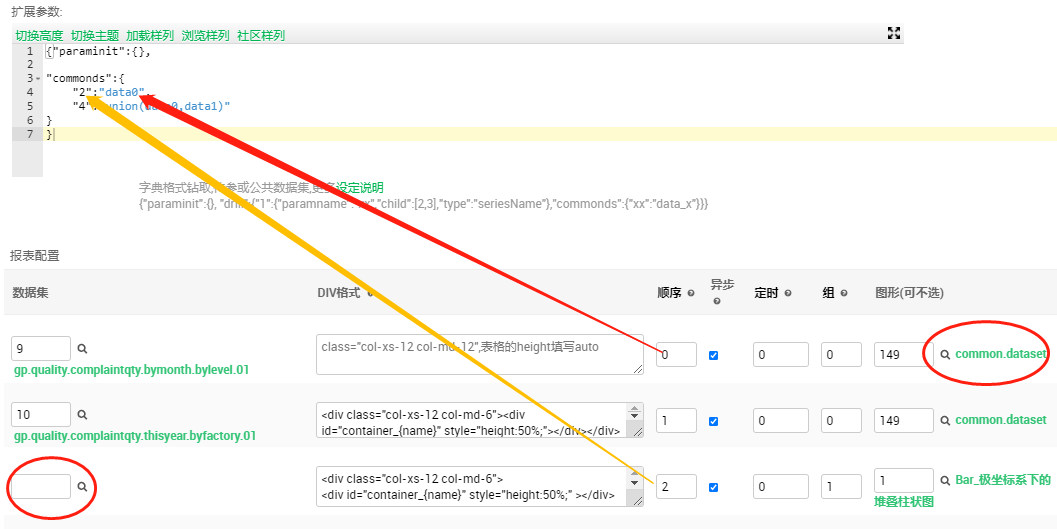
可视化开发界面也会有体现此图形所用到的公用数据编号
常规用法
如果使用到公共数据集, 最简单的方法就是在dashbaord的高级中进行设定,
{
"paraminit":{},
"commonds":{
"4":"data0",
"5":"ds_leftjoin(data1,data0)",
"6":"ds_union(data1,data0)",
"7":"ds_union(data0,data1,withhead=false)",
}
}
//使用说明
4,5,6,7是指的需要替换的数据集, data0, data1 是公共数据集,
如4号图形的数据集会被 data0替换, 5号图形会使用自身的数据和data0进行leftjoin
withhead 参数指数据join或union的时候, 是否要考虑头部, 比如:
a = [['A','C1','C2'],['L1',1,2],['L2',1,2]]
b = [['A','C3'],['L2',5]]
那么 ds_leftjoin(a,b), 默认是带头的,结果是:
[['A','C1','C2','C3'],['L1',1,2,0],['L2',1,2,5]]
如果 ds_leftjoin(a,b,withhead=false), 就是不考虑表头,则结果是:
[['A','C1','C2',0],['L1',1,2,0],['L2',1,2,5]]
再比如:
a = [['A','C1','C2'],['L1',1,2],['L2',1,2]]
b = [['A','C1','C2'],['L3',5,6]]
那么 ds_union(a,b) 默认是带头部的, 会自动去除掉b的头部, 结果为:
[['A','C1','C2'],['L1',1,2],['L2',1,2],['L3',5,6]]
ds_union(a,b,withhead=false), 结果为:
[['A','C1','C2'],['L1',1,2],['L2',1,2],['A','C1','C2'],['L3',5,6]]
共用数据预处理
你的公用数据一般可能是数组格式, 你可能想要对进行一些处理, 比如转化成字典格式, 然后你可以在这个图形中进行数据处理即可
//转化为字典格式
data__name__ = ds_createMap(__dataset__)
定制化用法
如果你有更多自定义的需求,在其它的图形中, 你就可以这样引用这个变量:
data__name__ = __dataset__;
dataset = ds_union(dataset,data3);
dataset = ds_leftjoin(dataset,data3);
或者直接取 data3的值, data3[0]....等等
需要注意的是, 如果你想要其它dataset能用到些公用变量,
请将此公用变量的dataset顺序排在其它dataset的前面
最后, 由于这会打乱图形的标准化开发, 所以不是特殊需求, 尽量避免这种用法